
开始您的AI 之旅
立即注册,获得10元算力币
输入手机号注册
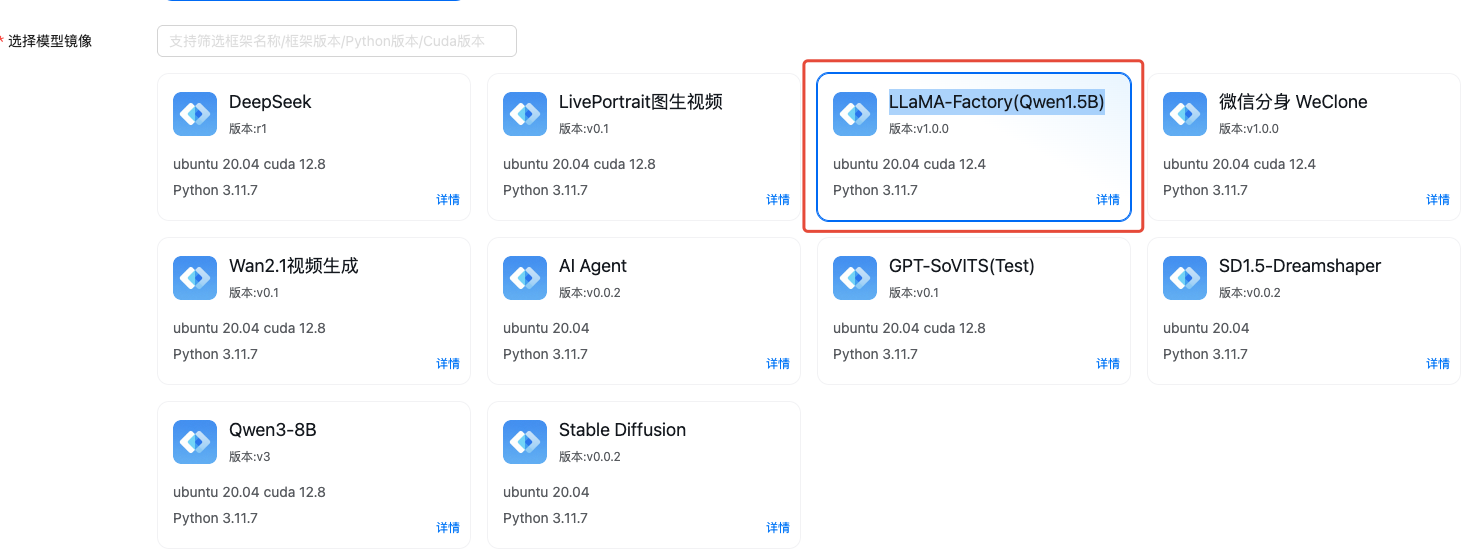
立即注册LLaMA-Factory 是一个开源的轻量级大语言模型(LLM)微调工具包,由南京大学人工智能创新研究院开发。它旨在简化大模型(如 LLaMA、BLOOM、GPT-2 等)的微调流程,仅需单张消费级显卡即可完成训练,大幅降低了开发者使用大模型的门槛。
新手可以申请云算力测试,加快速度,比如算多多、优云智算、算家云、九章算力、Autodl等,这里以算多多为例介绍流程。
用以下链接注册可以免费使用4070(36小时,?) 算多多GPU
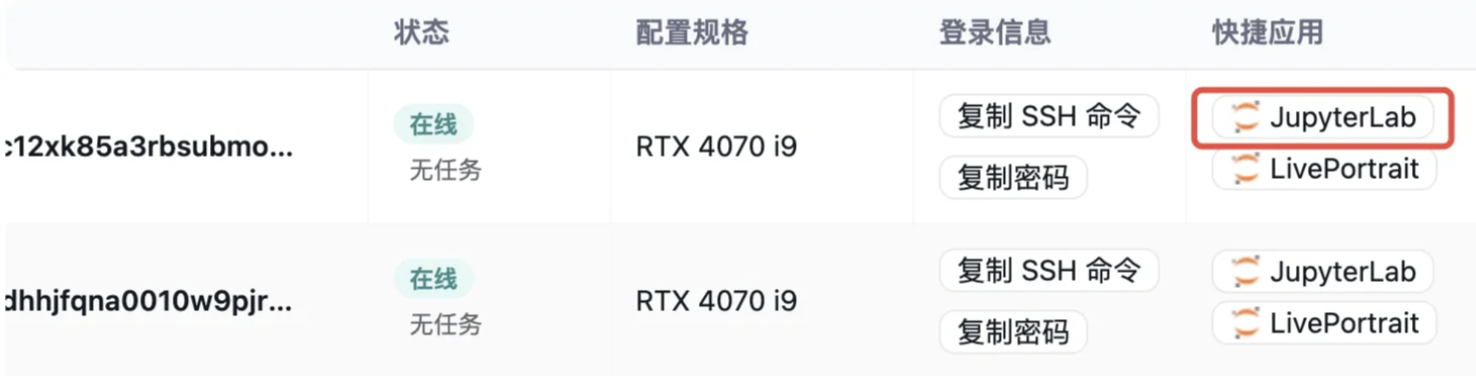
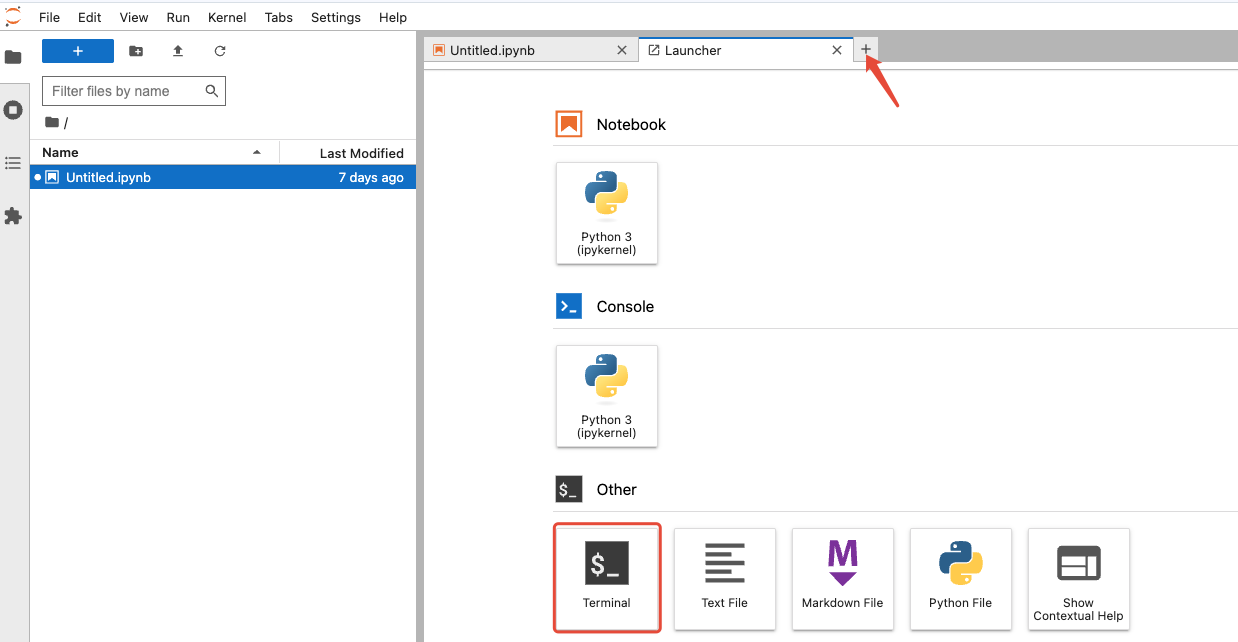
sudo -i
cd /root/LLaMA-Factory
conda activate llama_factory
llamafactory-cli webui
看到下述输出,代表web 服务启动成功,可以使用 web 微调了:
Visit http://ip:port for Web UI, e.g., http://127.0.0.1:7860
* Running on local URL: http://0.0.0.0:7860
* To create a public link, set `share=True` in `launch()`.
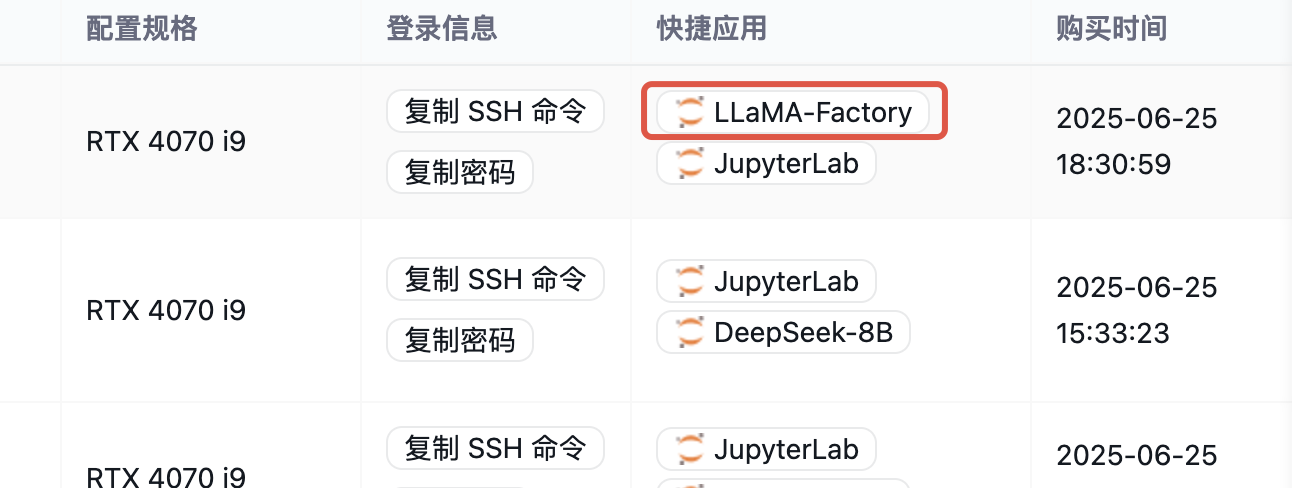
镜像已下载了Qwen2-1.5B-Instruct 模型,建议第一次体验的同学保持默认参数不动
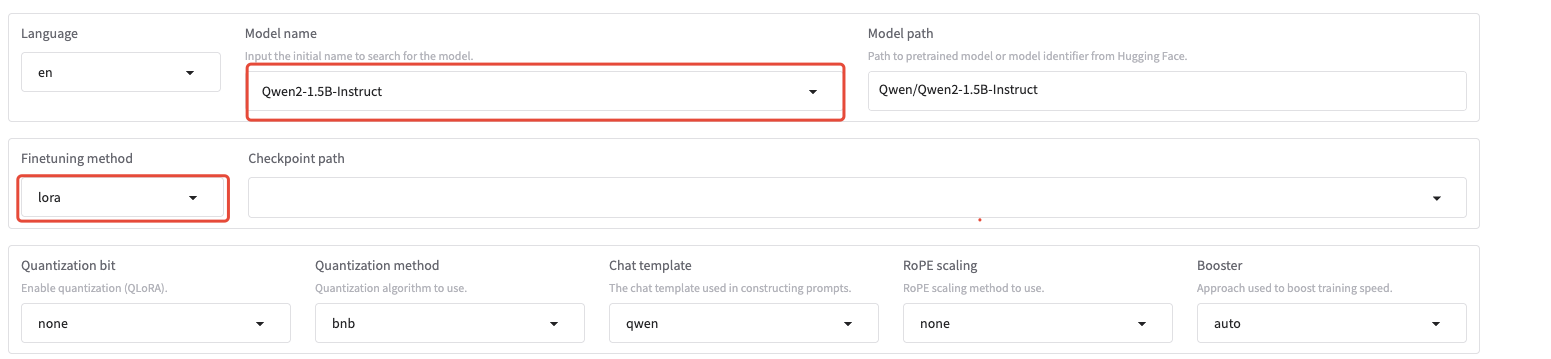
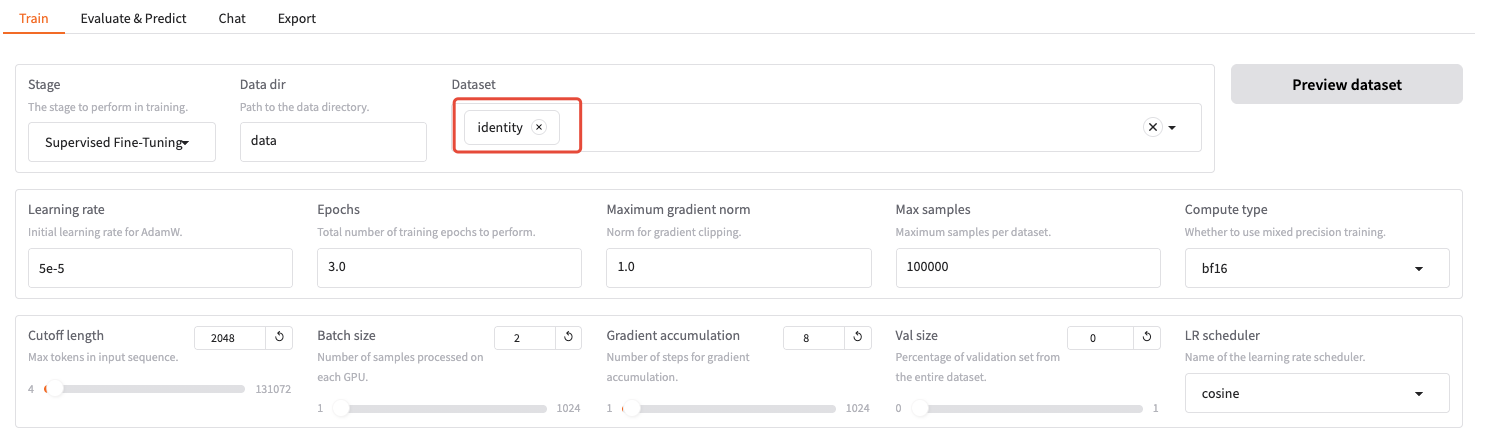
选一个数据集(你可以先点击旁边的"Preview dataset"按钮预览数据)
如果需要添加自定义数据集,请在
/LLaMA-Factory/data/dataset_info.json文件里添加对应的数据集
拉到下面,点击"Start"开始微调
你可以在 web 界面和终端上看到对应的进度
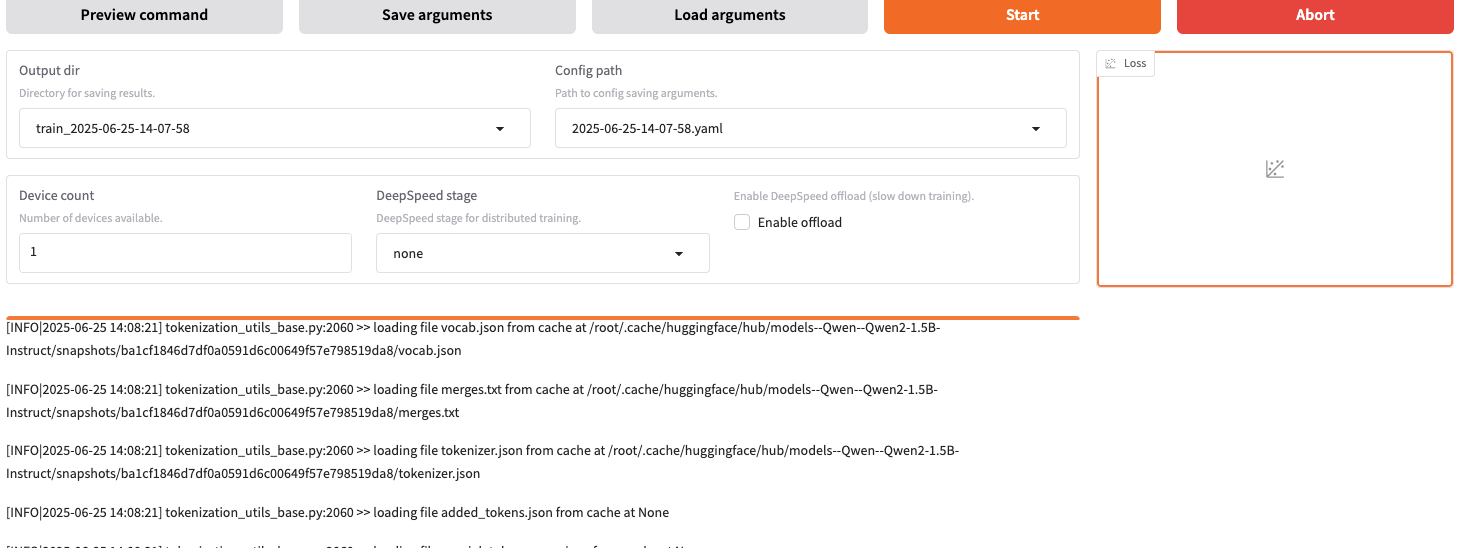
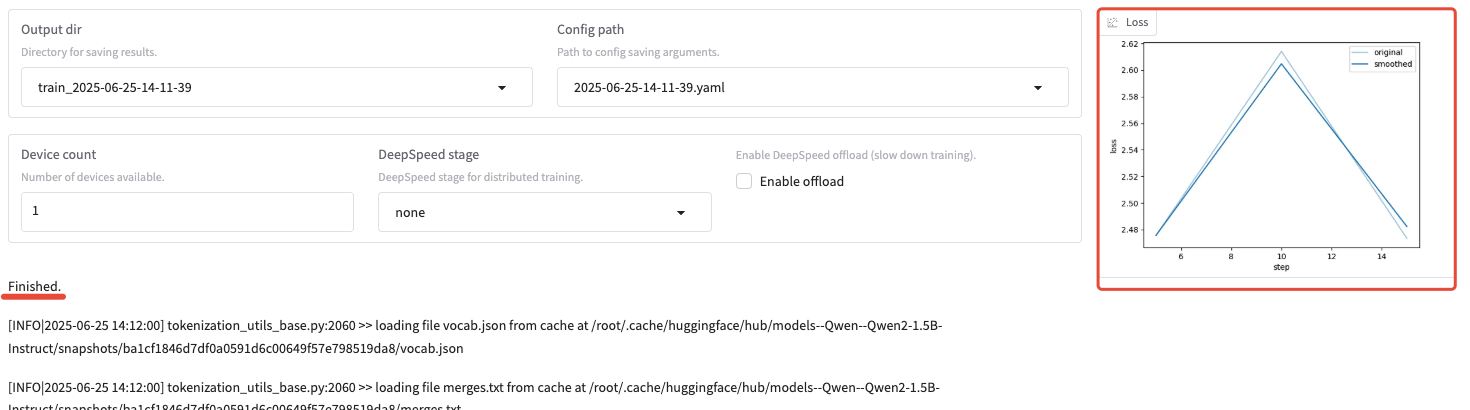
等待 5-10 分钟,微调完成后,你可以在界面上看到 loss 曲线。
微调好的模型保存在 /opt/LLaMA-Factory/saves/。
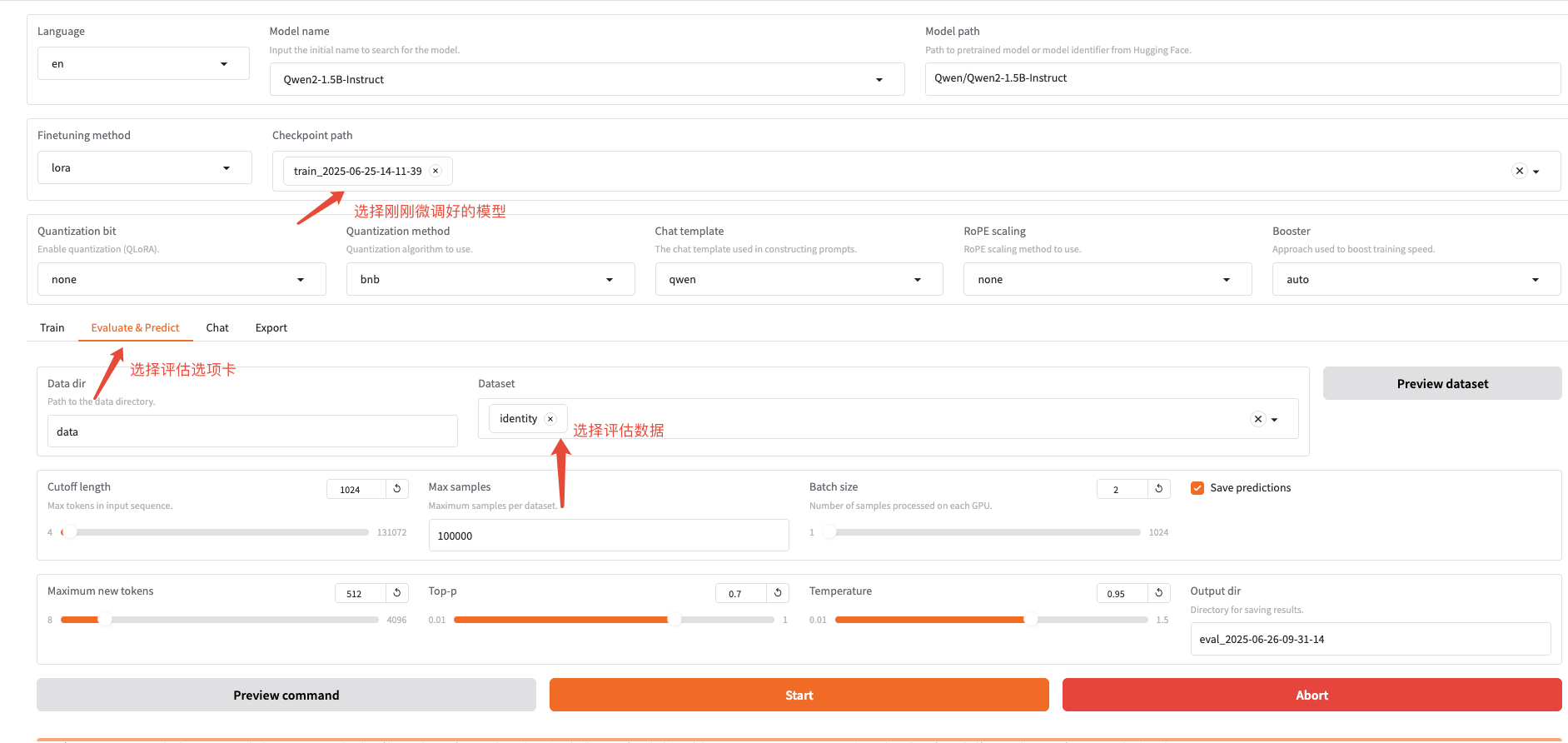
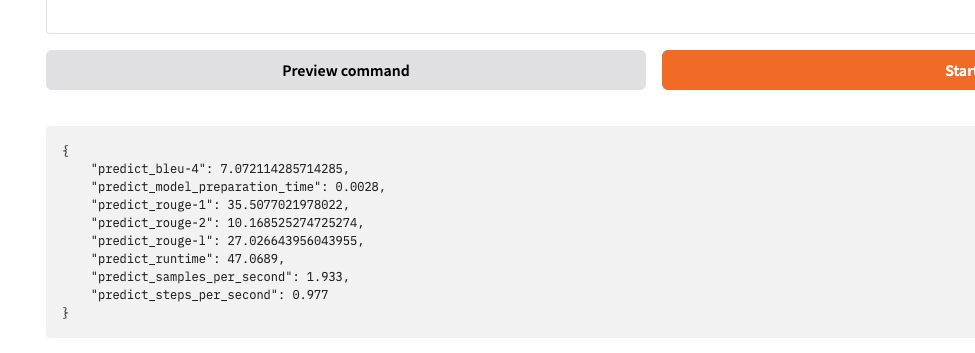
实例终端也可以看到评估结果:
***** Running Prediction *****
[INFO|trainer.py:4291] 2025-06-26 09:42:36,284 >> Num examples = 91
[INFO|trainer.py:4294] 2025-06-26 09:42:36,284 >> Batch size = 2
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 46/46 [00:45<00:00, 2.10s/it]Building prefix dict from the default dictionary ...
Loading model from cache /tmp/jieba.cache
Loading model cost 0.499 seconds.
Prefix dict has been built successfully.
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 46/46 [00:46<00:00, 1.00s/it]
***** predict metrics *****
predict_bleu-4 = 7.0721
predict_model_preparation_time = 0.0028
predict_rouge-1 = 35.5077
predict_rouge-2 = 10.1685
predict_rouge-l = 27.0266
predict_runtime = 0:00:47.06
predict_samples_per_second = 1.933
predict_steps_per_second = 0.977
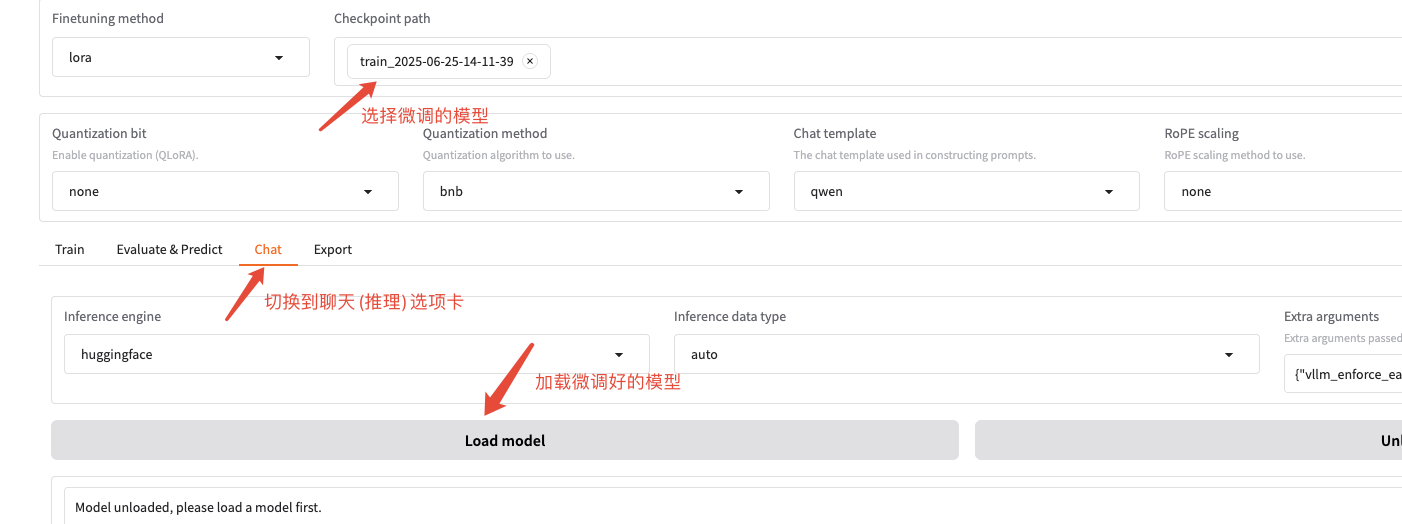
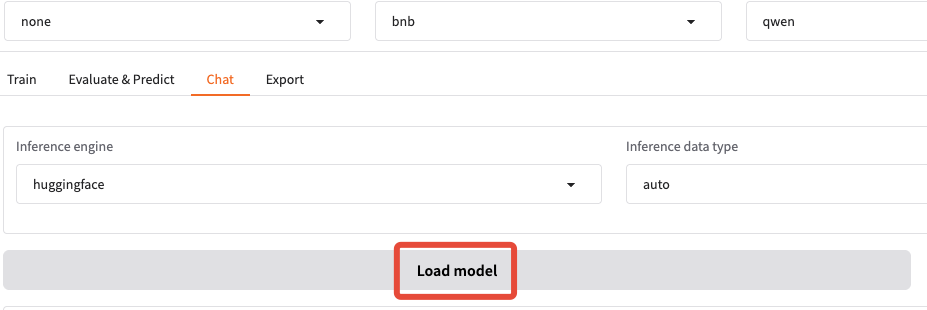
看到下面的界面代表加载成功
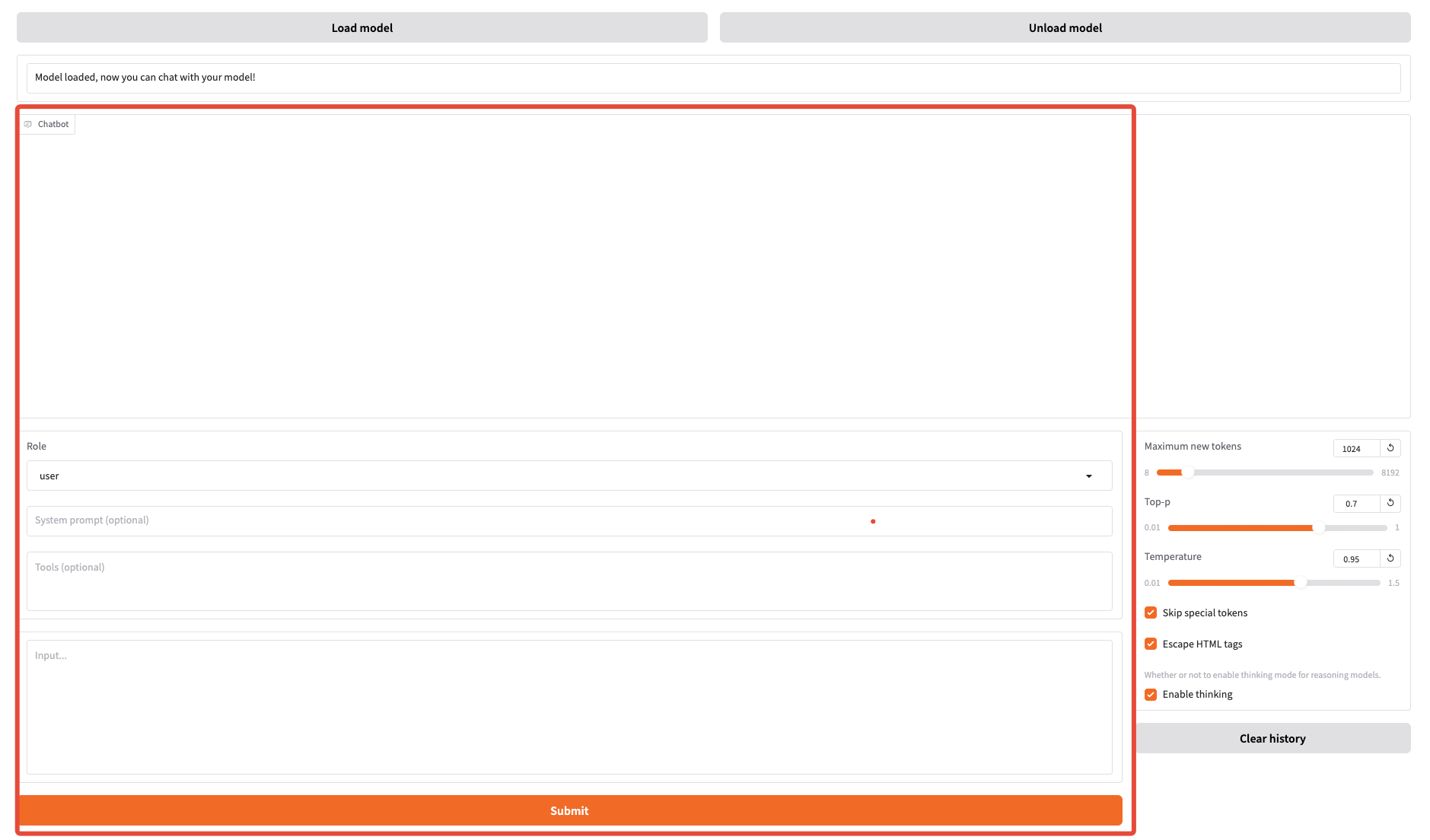
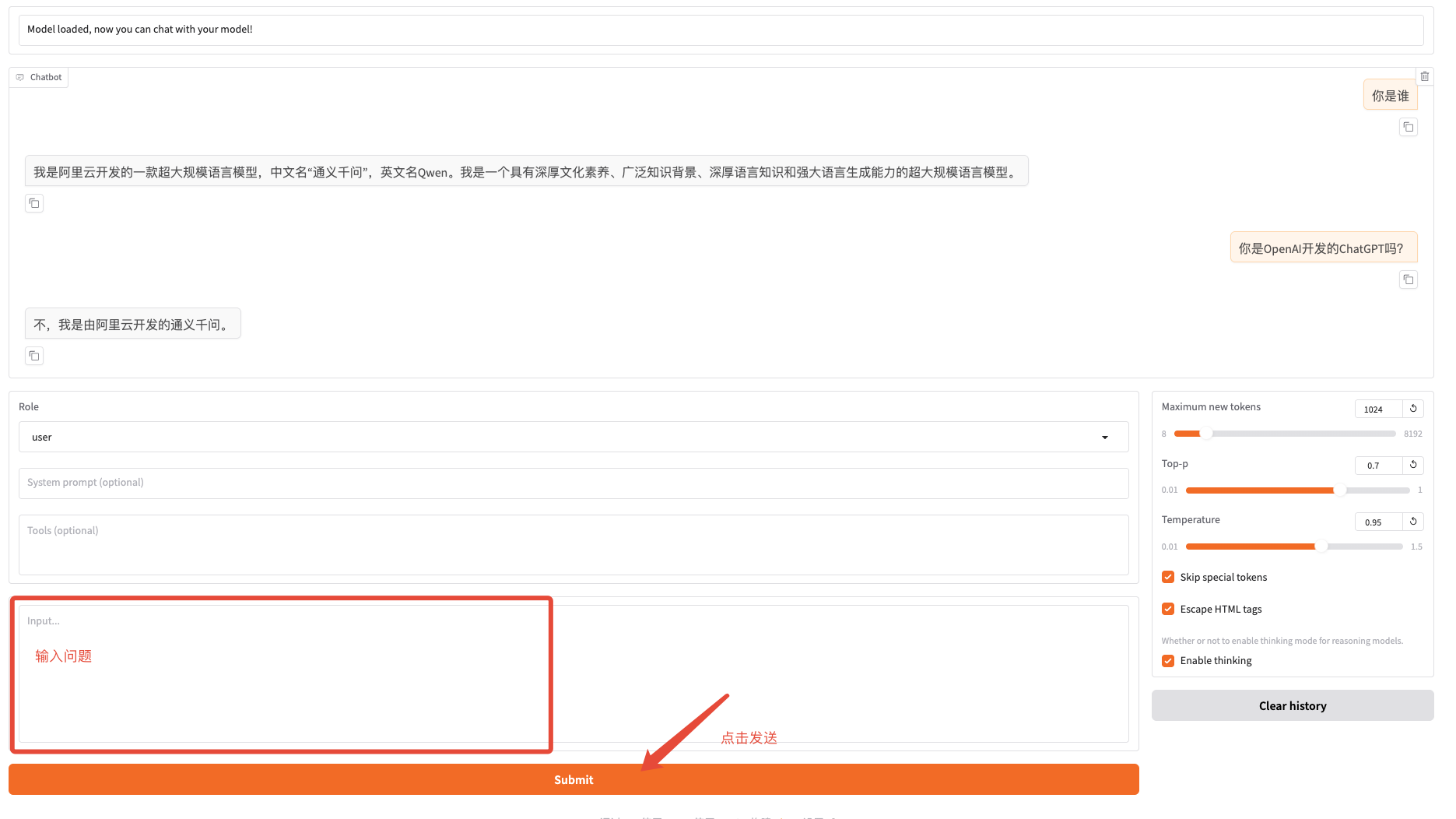
./saves/ 下
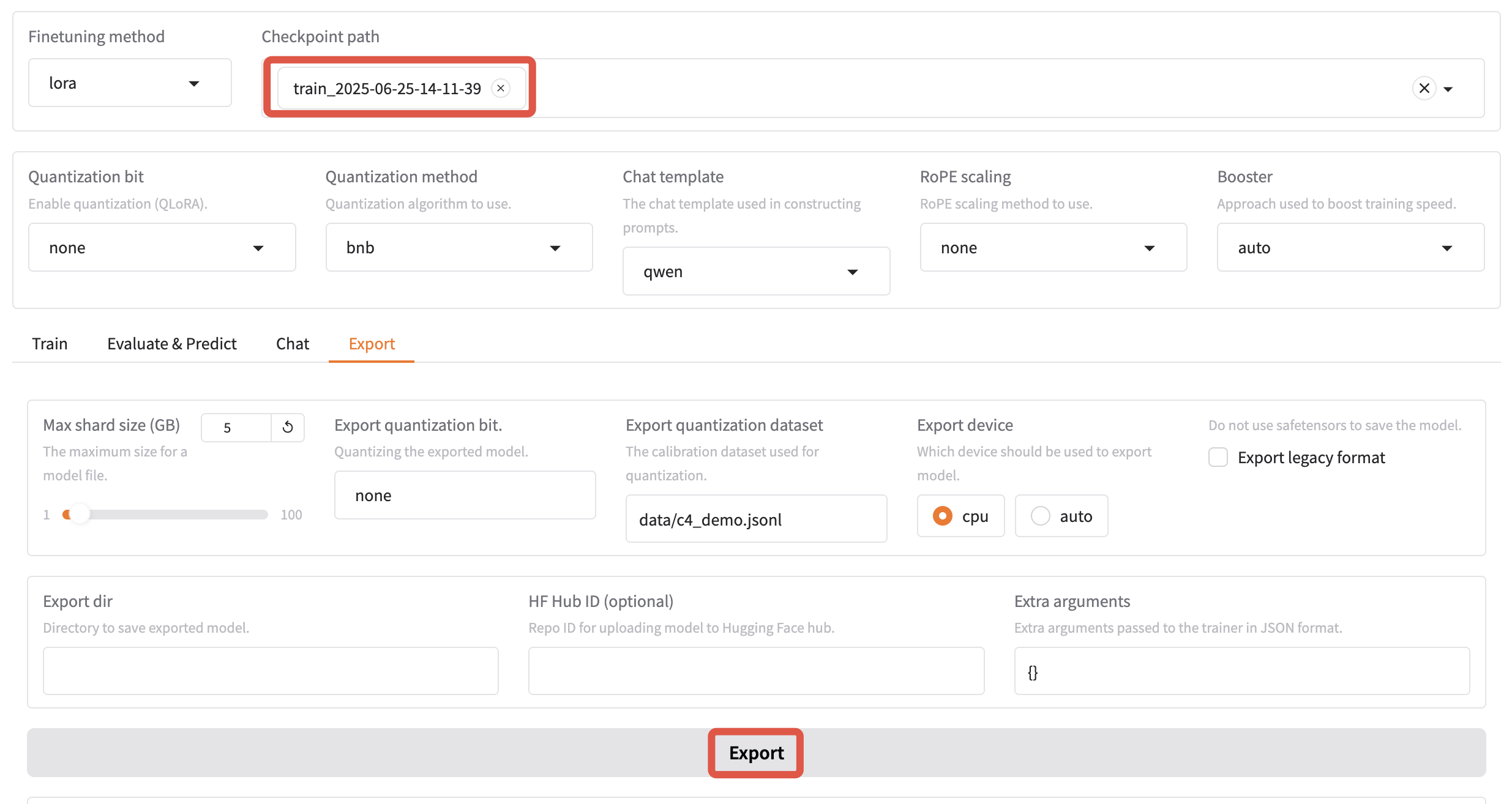
导出成功后,会生成 Modelfile config.json generation_config.json model.safetensors special_tokens_map.json tokenizer.json tokenizer_config.json 这些文件。
导出后的模型就可以使用 ollama 进行实际的推理了,具体的使用教程后面有需要再进行详细介绍。
至此,我们完成了使用 LLaMA-Factory 进行微调推理的核心流程,更多功能可以参考官网或者知乎的教程:
加入讨论群,联系管理员领取额外48 小时 4070 免费额度:
